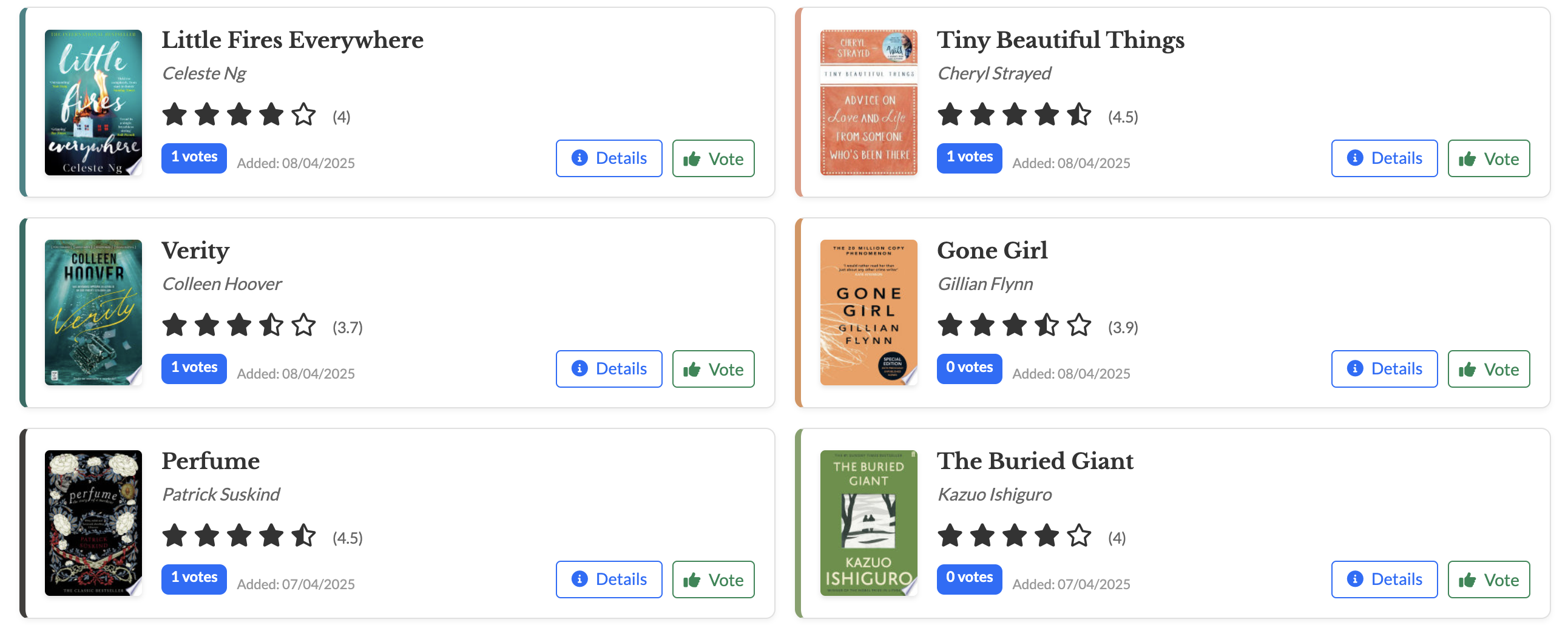
The Hardcover API is a powerful tool for developers building book club applications. In this technical deep dive, I'll share how I integrated the Hardcover API alongside Google Books and Open Library to create a rich book discovery experience.
- Why Hardcover API?
- Setting Up the Hardcover API
- Enhancing Data with Google Books and Open Library
- Visualizing Ratings
- Caching and Performance
- Challenges and Solutions
- Conclusion
Why Hardcover API?
Hardcover is a relatively new player in the book tracking space, but it offers several advantages that make it an excellent choice for developers:
- Rich GraphQL API: Unlike REST APIs that might require multiple requests to gather comprehensive data, Hardcover's GraphQL API allows you to specify exactly what data you need in a single request.
- Community-driven data: Hardcover has a passionate community of readers who contribute ratings, reviews, and tags, making the data particularly valuable for book recommendations.
- Detailed book metadata: Beyond basic information, Hardcover provides ratings distributions, user read counts, and genre tags that help create a more engaging user experience.
Setting Up the Hardcover API Integration
To use the Hardcover API, you'll need to obtain an API key. Once you have your key, you can start making GraphQL requests to their endpoint at https://api.hardcover.app/v1/graphql.
Here's how I structured my Hardcover API integration:
def search_book(title, author=None, bypass_config_check=False):
"""
Search for a book on Hardcover by title and optionally author using GraphQL.
"""
# Set up the headers with the API key
headers = {
"Authorization": api_key,
"Content-Type": "application/json"
}
# Use different queries based on whether author is provided
if author:
# Query with both title and author
query = """
query BooksByUserCount {
books(
where: {contributions: {author: {name: {_eq: $author}}}, title: {_eq: $title}}
limit: 1
order_by: {users_count: desc}
) {
title
pages
release_date
description
rating
ratings_count
users_read_count
users_count
id
slug
cached_tags
contributions {
author {
name
}
}
ratings_distribution
}
}
"""
else:
# Query with title only
query = """
query BooksByUserCount {
books(
where: {title: {_eq: $title}}
limit: 5
order_by: {users_count: desc}
) {
title
pages
release_date
description
rating
ratings_count
users_read_count
users_count
id
slug
cached_tags
cached_contributors
contributions {
author {
name
}
}
ratings_distribution
}
}
"""
# Execute the query and process the response
# ...Handling the GraphQL Response
One of the challenges with GraphQL is properly handling the response. Here's how I extract the relevant information from the Hardcover API response:
# Extract the relevant information from the response
book_info = {
'title': best_match.get('title', ''),
'author': author_name,
'authors': authors,
'description': best_match.get('description', ''),
'rating': rating,
'rating_count': best_match.get('ratings_count'),
'users_read_count': users_count,
'cover_url': best_match.get('cover_image_url'),
'hardcover_id': book_id,
'hardcover_url': id_based_url,
'hardcover_title_url': slug_based_url,
'published_date': best_match.get('release_date'),
'publisher': best_match.get('publisher', {}).get('name') if best_match.get('publisher') else None,
'page_count': best_match.get('pages'),
'isbn': best_match.get('isbn_13') or best_match.get('isbn_10'),
'ratings_distribution': best_match.get('ratings_distribution', []),
'cached_tags': best_match.get('cached_tags', {})
}Enhancing Book Data with Multiple Sources
While Hardcover provides excellent data, no single API is perfect. To create a more comprehensive book database, I implemented a multi-API approach that combines data from several sources:
Why Use Multiple Book APIs?
Different APIs excel in different areas. Hardcover offers excellent community ratings and tags, Google Books provides preview links and categories, and Open Library has extensive bibliographic data. By combining these sources, you can create a more complete book profile.
1. Google Books API
Google Books offers a vast catalog and doesn't require an API key for basic usage, making it an excellent complementary source:
def get_book_info(title, author=None):
"""
Search for a book on Google Books by title and optionally author.
"""
# URL encode the title for the API request
encoded_title = quote(title)
# Get the country code from config (defaults to GB for UK)
country_code = current_app.config.get('GOOGLE_BOOKS_COUNTRY', 'GB')
# Construct the search URL with country parameter
if author:
encoded_author = quote(author)
url = f"https://www.googleapis.com/books/v1/volumes?q=intitle:{encoded_title}+inauthor:{encoded_author}&country={country_code}"
else:
url = f"https://www.googleapis.com/books/v1/volumes?q=intitle:{encoded_title}&country={country_code}"
# Make the request and process the response
# ...2. Open Library API
Open Library is an open-source project that provides free access to bibliographic data:
def search_book(title, author=None, bypass_config_check=False):
"""
Search for a book on Open Library by title and optionally author.
"""
# URL encode the title for the API request
encoded_title = quote(title)
# If author is provided, try searching by both title and author first
if author:
encoded_author = quote(author)
search_url = f"https://openlibrary.org/search.json?title={encoded_title}&author={encoded_author}"
else:
# If no author provided, search by title only
search_url = f"https://openlibrary.org/search.json?title={encoded_title}"
# Make the request and process the response
# ...Visualizing Ratings Distribution
def generate_ratings_histogram(ratings_distribution):
import matplotlib.pyplot as plt
ratings = sorted(ratings_distribution.items())
labels, values = zip(*ratings)
plt.bar(labels, values)
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('Ratings Distribution')
plt.show()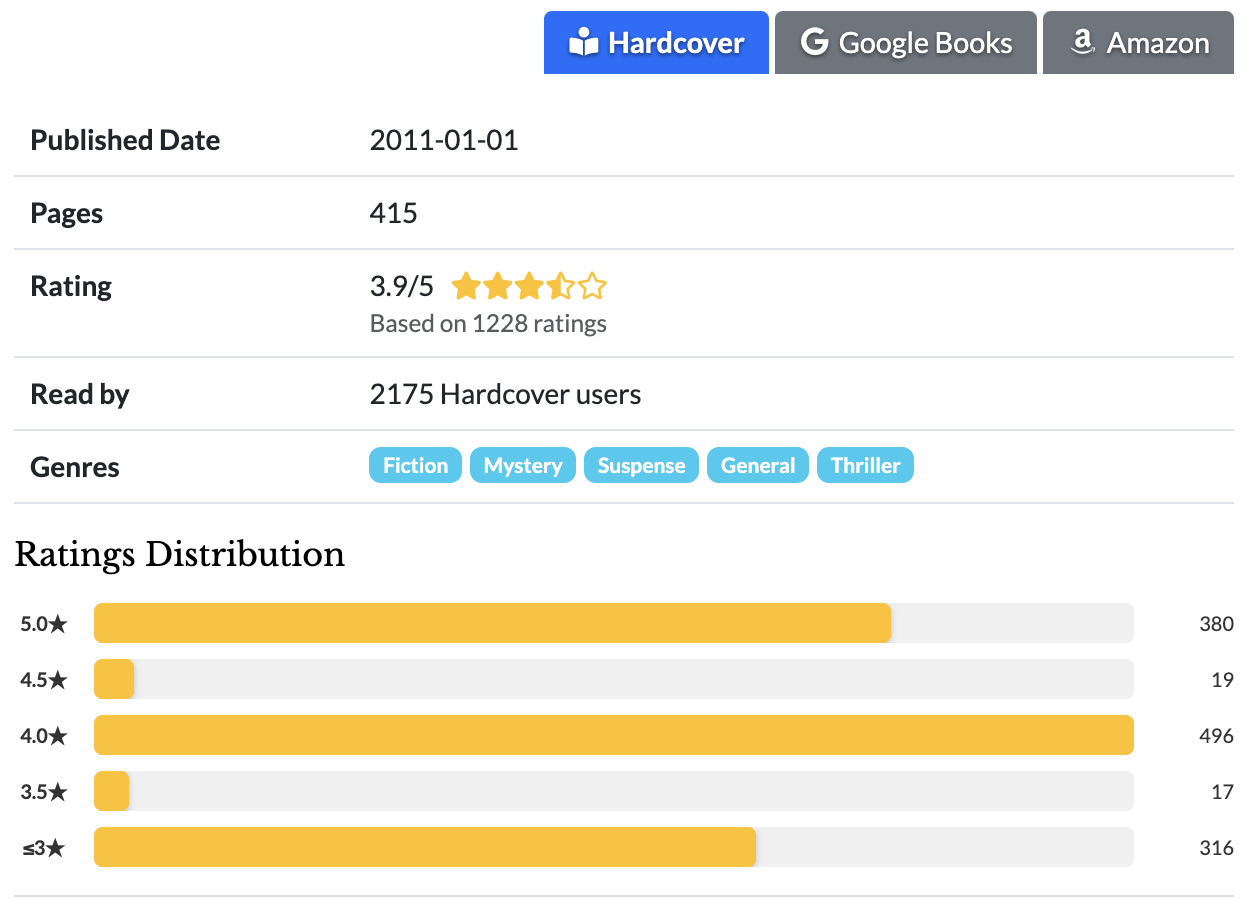
Challenges and Solutions
Challenge 1: Inconsistent Book Metadata
Different APIs may return slightly different titles, authors, or publication dates for the same book.
Solution: Implement fuzzy matching and normalization:
# If that fails, try with title() applied to both title and author
if not book_info and title:
title_cased_title = title.title()
title_cased_author = author.title()
if title_cased_title != title or title_cased_author != author:
book_info = _execute_hardcover_query(query, title_cased_title, title_cased_author, headers)Challenge 2: Rate Limiting
Most APIs have rate limits that can affect your application's performance.
Solution: Implement exponential backoff and request queuing:
# Make the GraphQL request with increased timeout
response = requests.post(
"https://api.hardcover.app/v1/graphql",
headers=headers,
json=payload,
timeout=30 # Increased timeout from 10 to 30 seconds
)Challenge 3: Handling Missing Data
Not all books will have complete data in every API.
Solution: Combine data from multiple sources to create a more complete profile:
# Get Google Books information to supplement Hardcover data
google_book_info = None
if book_info.get('title') and book_info.get('author'):
google_book_info = get_google_book_info(book_info['title'], book_info['author'])Conclusion
Integrating the Hardcover API alongside other book data sources has significantly enhanced our book club application's capabilities. The GraphQL-based approach of Hardcover makes it particularly developer-friendly, while the combination with other APIs ensures comprehensive coverage.
For developers looking to build book-related applications, I highly recommend considering Hardcover as your primary data source, supplemented by Google Books, and Open Library.
By implementing a multi-API strategy with proper fallbacks, caching, and performance optimizations, you can create a rich book discovery experience that delights your users.
Try Our Book Club Platform
Experience the power of these API integrations firsthand by using our Book Club platform. Sign up for free and see how we've implemented these techniques to create a seamless book discovery experience.
